

The power to bring data together rather than just moving or rearranging it is harnessed in FME through the merging and joining of data from multiple datasets regardless of type.
With the large number of supported applications and data types there is a transformer that is suitable for both the type of joins you are looking to make, your skill level or personal preference. There are many ways to achieve bringing data together and each has its own advantages. Here’s a quick guide to help you see what transformers are available to you for merging your data and some simple tools to help check and balance.
Data integration
FME Workbench allows you to author the flow of data from one place to another and help break down data silos that often result in organisations with many applications and data formats. FME offers multiple paths to bring all your data together. The large range of transformers available make it easy to merge and join data as they do the heavy lifting and as you learn from, and about your data it becomes easier.

Merging and joining data is the process of bringing data together using a common identifier, adding to the table horizontally, resulting in the table containing all or selected attributes from both data sets. Compared to a union or appending of data to a table, where using the same schema data is combined (added into the table) vertically which increases the number of records. In a workspace, data can be joined internally (meaning the data is already in the workstream) or externally (data is not in the workbench and needs to be read in) depending on where in the workstream the join occurs. Some transformers are blocking transformers which means they wait for all the features to arrive before processing, which helps with grouping of data. Safe Software have put together a flow chart that helps with the different transformers which can be found here. Now let’s look at the transformers.
Transformers
FME offers a range of ways to perform similar transformations giving you the ability to choose based on your own comfortability and skill level or a personal preference. There are two main categories of data merging or joining transformers which are either SQL or SQL free – meaning you can have little to no SQL experience or be a SQL pro. Transformers that use SQL include InlineQuerier, SQLCreator, and the SQLExecutor and non-SQL transformers that perform in the same way as the SQL transformers are the FeatureJoiner, FeatureMerger, FeatureReader and the DatabaseJoiner. The choice of transformer also depends on where the merging/join function is happening within the workspace.
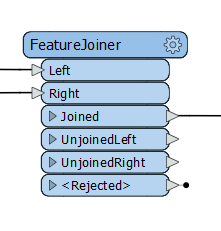
FeatureJoiner
Has SQL like function without SQL by using SQL terminology and is a simple and faster way to perform Left, Inner and Full joins. It can use any FME reader and has two ports one for the left and one for the right, which are then joined using a unique key. It is easy to set up and handles cardinalities and multiple matches. The data is already loaded, and any source can be used. But if your data is already located in a SQL data source it would be faster to use the SQL executor or SQL creator.
Quick Facts
- Uses SQL Free joins
- Very easy to set up
- Great performance
- No prior SQL knowledge needed
- Blocking
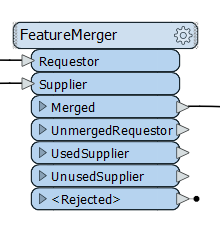
FeatureMerger
The FeatureMerger merges attributes and or geometry of two sets of features based on a common key attribute or expression, from any FME reader. Requestors are the features that receive the new attributes or geometry and if any of the attributes are the same, they can be set to be preserved or overridden. The FeatureMerger allows you to process duplicates and generate a list of selected attributes from the matches.
Quick Facts
- Many suppliers can be merged onto single requestor
- 1:M joins bit more work
- Single match is output for 1:M relationship
- Can create geometries
- Blocking
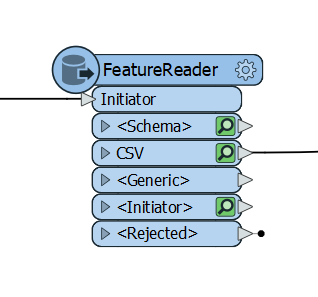
FeatureReader
A FeatureReader transformer reads in data the same as a reader but can be used midstream for any FME supported format. Requiring an initiator to read in the features data, it is then routed through named or generic ports and can join data from any database or spatial format, which is often the most typical usage. It also has the ability to specify a WHERE clause or a spatial filter for formats that support this function.
Quick facts
- Simpler midstream option that adds and joins data quickly
- Join against any database or spatial format
- Typically used for spatial joins
- Also used to perform tabular joins with database tables
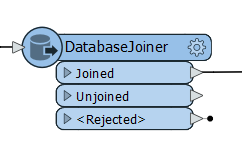
DatabaseJoiner
Let’s you connect and join your database tables (including Excel or CSV) all in one transformer as it connects midstream and joins to an external database, requiring no SQL knowledge. It needs at least one common attribute or key to join on and it also has a neat feature that gives you upfront control of what attributes you want to add into your workflow. Matching and accumulation options give you the ability to set cardinality and how multiple matches are given. It also provides the ability to optimize by prefetching records in the database giving better performance.
Quick facts
- Non-blocking – joins features as they are read in
- Can also connect to excel and csv
- Good for quick look ups – caches first 5000 records (best if the join data is larger or changing)
- Data external to the database can be changed without editing the workspace
InlineQuerier
Creates temporary SQL lite database tables from any incoming features while executing SQL (SQLite) queries, even if they didn’t originate from a SQL supporting. This allows you to execute multiple complex queries, joining data all in one transformer and outputting the results of the query, making it a great replacement if you have multiple FeatureMerger’s in a workflow. The InlineQuerier dynamically adds the inputs and outputs that are the SQL queries. If your data is already in a database or you are looking at doing simple tasks like filtering or attribute mapping, then look at using another transformer.
Quick facts
- Data already loaded, from any data source
- Utilizes power of SQL
- Only preserve attributes used in query to reduce indexing in the transformer and FME recovers attributes on output as it can take a while to load
SQLExecutor
The SQL Executor queries against a (SQL-enabled) database and requires an incoming feature to trigger the SQL statement. You can use any type of SQL that you prefer, it lets you preform table operations and if your table supports spatial then you can also use spatial queries.
SQLCreator
The SQL Executor queries against a database, does not require an incoming feature to be triggered and it also supports spatial. SQL queries are in the transformer and the appropriate syntax needs to be used for the database being queried.
Quick Tips for the SQLCreator and SQL Excecutor
- Let the database do the work – only load what you need
- Data needs to be in a single database
- SQL friendly – any level of complexity
- For simple joins look at using the DatabaseJoiner
AttributeValueMapper
For simple joins that just need to be mapped, the AttributeValueMapper allows you to have a user defined set of attributes in a look up table that map new values or alter attribute fields. This is great for a join that has no external dependencies, can be imported at the time of workspace design from an external source and is most commonly used to add or alter, clean up or create alternate attribute values.

Quick Tips
- Good for small simple stable mappings
- Only a single attribute added
- 1:1 lookups
- Very fast
- Non-blocking
Conclusion
By choosing the right transformer you can merge and join data more efficiently, whether you use SQL or SQL free transformers, either load the data or let the database do the work.